

您现在的位置:首页 > 自动驾驶数据闭环:实现高阶自动驾驶的必由之路
自动驾驶数据闭环:实现高阶自动驾驶的必由之路
自动驾驶量产落地离不开车辆的“感知”、“决策”与“执行”。
随着感知技术与计算平台的逐渐成熟与趋同,影响高阶自动驾驶落地的关键因素不再是解决常见的一般案例(common case),而是解决“路口”问题,也即各类不常见但不断出现的“长尾问题”。
作为一种模仿人类的科学,AI自动驾驶与人类认知世界的逻辑基本一致,想让汽车更好地理解世界,就需要构建更精准的模型。但算法模型的建立并非一劳永逸,自动驾驶车辆在行驶过程中总会遇到各种陌生场景。
因此,如何对新场景数据进行大规模高效处理并快速优化算法模型,即成为自动驾驶技术迭代的关键。
换言之,构建基于数据驱动的自动驾驶数据闭环,让数据实现高效流动,是实现高阶自动驾驶的必由之路。
数据闭环不是一个新概念
数据闭环并非新概念,互联网时代早期即有广泛应用。
一个比较典型的例子即是各类软件、APP的“用户体验改进计划”。
用户在初次打开一款软件时,往往会弹出选项——是否加入用户体验改进计划。点击确定后,软件就会收集用户的使用信息。在出现崩溃、Bug等场景下,软件还会弹出信息,询问是否允许上传本次崩溃信息以帮助改进,比如Windows出现的各种错误报告。
点击提交后,软件开发商的工程师们会分析错误报告,以找出出现崩溃、Bug的原因,进而修改代码并在下次更新后予以解决。
用户在使用过程中遇到的所有问题均可以通过此种方式解决,周而复始,不断优化软件性能与使用体验,这就是一种传统的数据闭环。
这个过程可以用下图简单概括:
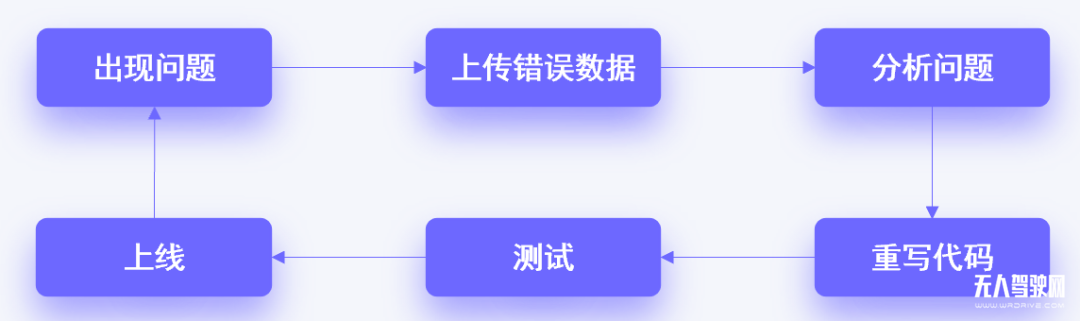
以上过程中,用户的使用数据是关键因素,它可以帮助工程师快速定位问题,并予以解决。
随着技术的进步,传统的数据闭环方式并没有被时代所淘汰,在自动驾驶技术开发中仍被广泛应用,但与以往又有些许不同。
自动驾驶时代的数据闭环
自动驾驶系统的研发与优化,与传统软件开发存在很多不同。
传统软件更多是在代码端解决各类问题,但自动驾驶系统除代码以外,还有更为关键的AI模型。代码端的问题可以通过传统的数据闭环方式予以解决,但模型端的调整则需要重新训练或优化AI算法模型。
因此,自动驾驶数据闭环需要在传统数据闭环方式上,引入一些新东西:
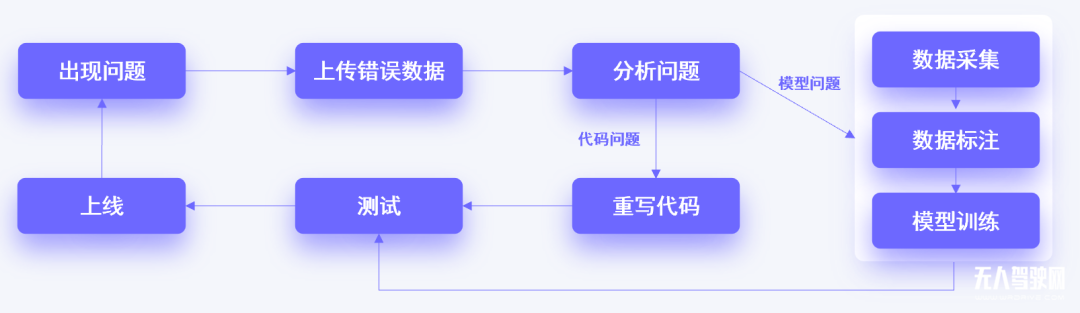
模型问题的解决流程可以进一步细化为:
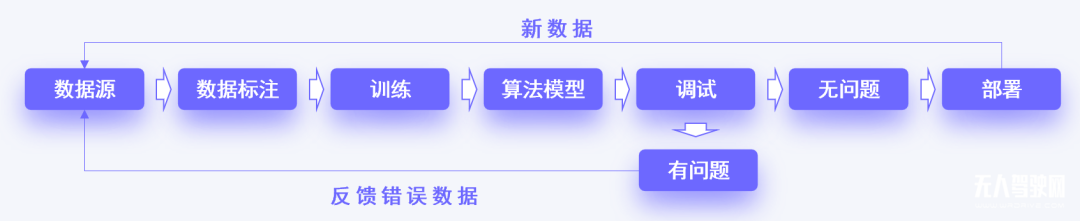
而支持自动驾驶数据闭环实现周而复始、不断向前的关键,也是新场景数据的不断投喂。
数据之于自动驾驶的重要性正被重新审视,各大自动驾驶厂商纷纷推出自己的数据闭环方案。
Tesla:核心为Autopilot数据引擎框架。获得数据后,先通过单元测试确认模型误差,然后进行数据清洗与标注,最后完成模型训练与部署。
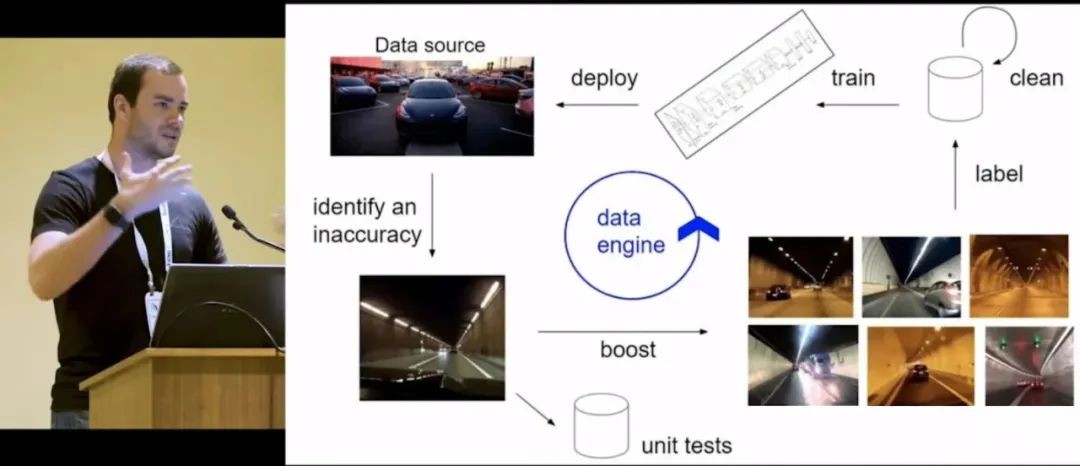
目前Tesla已经积累了上百亿英里的行驶数据,这些海量的真实路况数据,既是Tesla核心资产,同时也帮助Tesla实现了模型的快速迭代与升级,为率先抢占高级别的自动驾驶技术高地平添一大助力。
Waymo:相较于Tesla,Waymo引入了数据挖掘、主动学习、自动标注等模块,但基本的框架相差无几。获得数据来源后,通过数据标注获得数据真值,其中涉及到数据筛选、挖掘和主动学习,模型优化完成测试后,进行发布或部署。
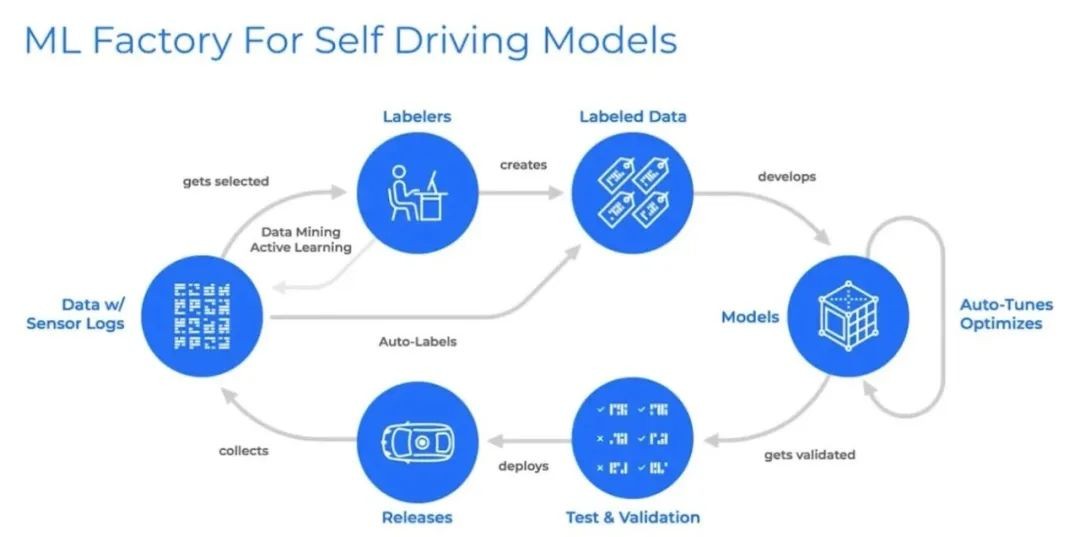
其他自动驾驶公司还会在数据闭环中引入仿真、计算等功能模块,但自动驾驶数据闭环通用基本框架可简化为:
数据采集-数据标注-模型训练-部署,如此周而循环往复。
数据高效流转是关键
现实驾驶场景难以穷尽,极其复杂且不可预测,需要AI模型快速迭代升级。实现自动驾驶数据闭环的快速循环迭代,以满足新场景模型适配问题,同时也需要各“长尾场景”数据的高效流转。
模型训练方面,目前AI算法模型已阶段性基本成熟。在实际应用时,不同场景需要解决的问题不尽相同。这并非算法模型的问题,而是场景适配度的问题。自动驾驶AI模型后续调优主要以数据迭代为主,需要投喂海量新场景数据。
数据采集方面,依靠遍布车身的各类传感器,车辆每小时采集的数据量可达数TB之多。然而采集得到数据为非结构化数据,这些未经处理的数据并不能直接用于模型训练,标注后才能产生使用价值。
横亘在数据与模型训练之间的首要问题是如何高效处理海量数据集,真实数据规模已然成为智能驾驶行业的“命脉”。
然而与指数型增长的数据服务需求相比,无论数据处理效率亦或是数据产出质量均难以满足市场需求。
产能方面,大部分数据服务商业务规模、执行效率与项目经理能力高度绑定,产能瓶颈问题凸显;数据产出质量方面,以点云数据为代表的数据处理需求占比逐渐扩大,传统依靠简单工具和依赖人力的业务执行方式,也早已无法满足垂直市场的需求。
自动驾驶实现规模化量产,数据服务领域能否率先实现突破将成为关键。
AI驱动的数据闭环
作为行业领先的数据服务厂商,曼孚科技深知自动驾驶数据服务行业痛点。
相较于传统SLG模式业务增长需要堆积人力的方式,曼孚科技回归科技创新本质,以PLG(产品驱动增长)模式代替SLG模式,重视产品力塑造,构建起高效的数据闭环,直击数据产能与数据产出质量两大核心痛点。
曼孚科技数据闭环方案以AI为主要驱动力,重视AI对数据标注的反哺作用,实现低成本量产高质量结构化数据;数据处理能力的提升为算法的训练与调优提供充足燃料,优质算法既可再次反哺数据标注,也可在部署应用中源源不断产出新数据,如此形成正向循环往复,实现高效迭代升级。
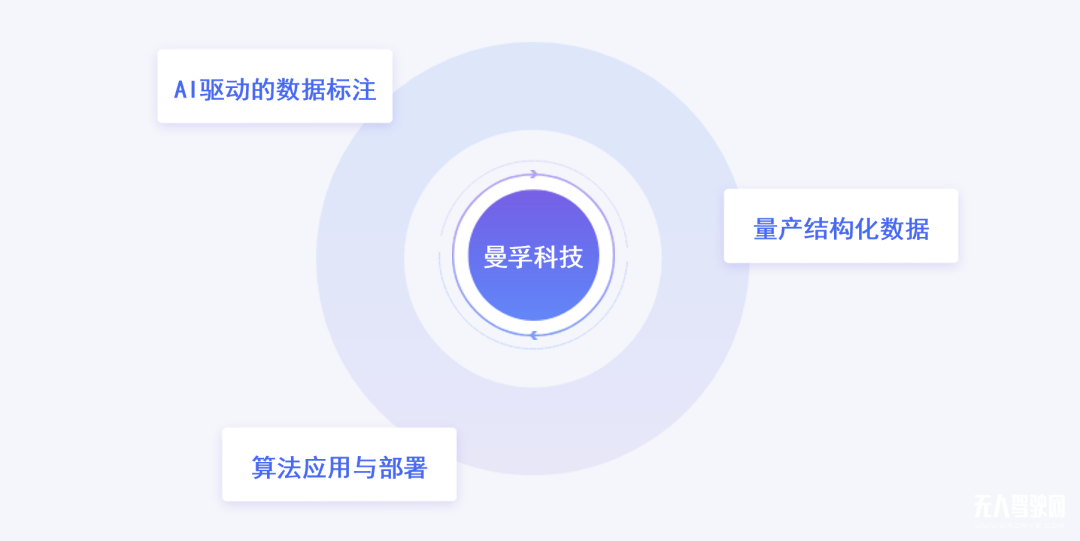
AI驱动的数据闭环
在自动驾驶数据标注方面,作为行业唯一聚焦自动驾驶赛道的数据智能平台,MindFlow SEED平台既支持2D图像场景下的车道线、车辆行人、泊车、全景语义分割等类型标注,也同步支持3D点云场景下的车路协同、连续帧、点云融合、点云语义分割等标注类型。
在增效降本方面,平台还创新性地引入自动化生命周期管理、AI增强等模块,AI标注平均准确率可达90%以上,部分场景可实现完全AI标注量产。
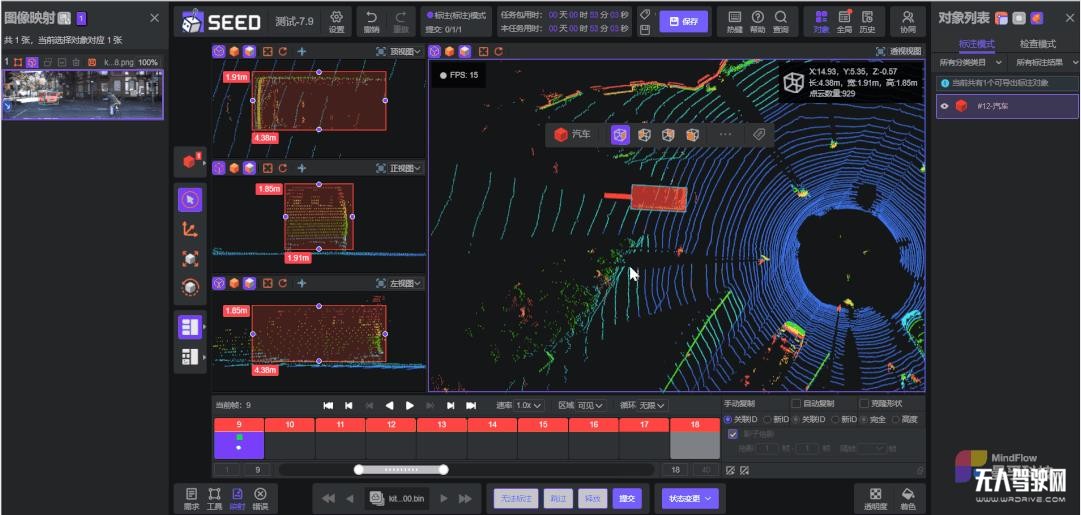
AI标注
(注:根据训练模型在已标注的测试集上进行预处理后通过IoU算法进行计算,IoU阈值在0.9以上算正确计算)。
凭借产品与流程上的创新变革,过往堆积人力的执行方式被平台产品所取代,业务执行规模不再与项目经理人数绑定,从源头端解决AI应用场景持续拓展对高质量多源异构数据的海量需求。
未来,曼孚科技将持续聚焦自动驾驶数据闭环构建,专注提升真实数据规模量产能力,为自动驾驶商业落地增添更多助力。